I try to stick a few Azure Data Factory design paradigms. One of them is to create re-usable artifacts. By creating these elements, you can make your ADF pipelines dynamic and have runtime values. Over the last two years, ADF has added a lot more parametrization options, but not everywhere you would want to use are they available.
Often, when a new connector source type is added, they may not have all the features available you want. For a while Snowflake, you couldn’t use dataset and linked service parameters. In fact, I started this blog a year ago, and Snowflake didn’t have…but by the time I got around to writing it, they had added.
However, recently I was working on implementing Mongo as a data source, and ran into the same issue. (So this time I am blogging before it changes. 😊 )
Linked Service Parameters
For many ADF linked service connectors, when you add, you can go down to the bottom of the fly out tab and you’ll see Parameters. You name the parameters, then can reference them in other places within the linked service setup. You’ll see a little “Add Dynamic Content” underneath text box, and when you use them the box will turn blue, indicating it is indeed dynamic.
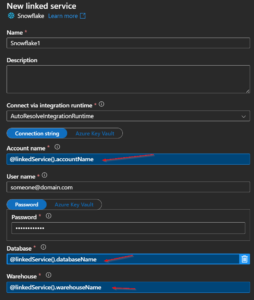
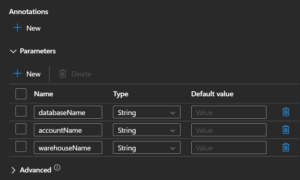
So in ideal workflow you’d have linked service parameters, that would show up in the dataset, and then you’d create dataset parameters and fill in the linked service parameters with them.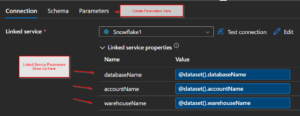
Then in the ADF activity, such as a copy activity, you’d see the dataset parameters. Then to go one step farther, you’d create pipeline parameters so you could make everything dynamic at run time. And all those dynamic elements would be obvious, or explicit, in UI.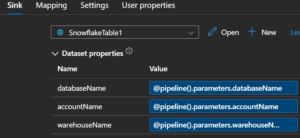
Linked Service WITHOUT Parameters
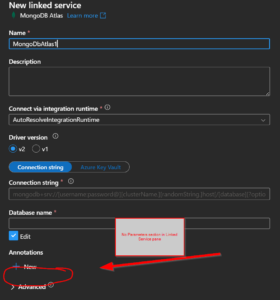
So above is the ideal scenario, where you can have this nice little chain of parameters.
But what if the Linked Service doesn’t have parameters. Can I make it dynamic or am I stuck with the purgatory of creating a ton of individual static linked service?
Luckily, we can use a lot of the same practices we have above and kinda hack our way through, but with a little less guidance from the UI.
Mongo right now happens to be a good example. When I open the linked service, there is not even a place for parameters (I’d like to rant about how they should have a template by now, but let’s set that aside). So this what I am shown.
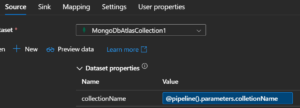
Even though I don’t have parameters, I can manually add the same pipeline parameters I used earlier and put it in the text box. However, notice that there is no “dynamic content” pop up and it didn’t turn blue. And I have to include these nice curly brackets, so ADF knows to consider it a parameter.
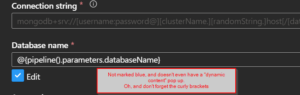
So it works, but I won’t see it indicated to me in the dataset, and since not in dataset, it won’t show up in pipeline authoring (since remember that is coming from the dataset, not the linked service itself).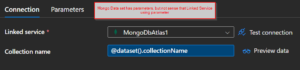
Pros and Cons
So we see that we can accomplish our goal, to make reusable artifacts in data factory that can be made dynamic, by passing in parameters from as high a level as possible, ideally at run time in pipeline.
However, those dynamic elements won’t be obvious. Meaning there is, for example, no way to preview data or test, because by definition I only have pipeline parameters, when running a pipeline. So if I want to test, I will need to manually change the linked service to a static value and preview, or run a pipeline, not exactly ideal. Also, when collaborating, the other users of your “implicit” linked service parameter won’t know to have that parameter in their pipeline, and even if they do, they have to make sure it is the same name, and is even case sensitive. So probably a handy idea to document it somewhere.
Ultimately, the positives of having this re-usable element rather than miasma of linked services, outweighs the negatives, but just keep them in mind.



